R语言|数据预处理方法
数据预处理的主要内容包括:
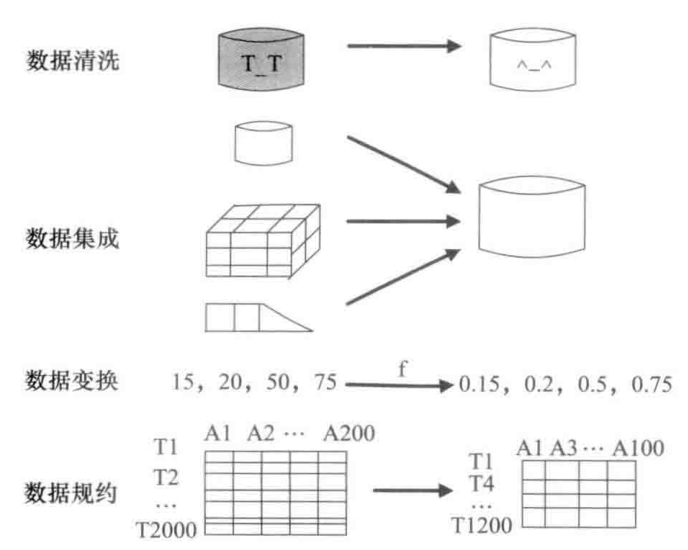
数据预处理的主要内容包括:
数据清洗
原始数据的质量直接影响了数据分析的质量,不符合要求的脏数据有:
- 无关数据。
- 重复数据或者含有特殊符号的数据。
- 缺失值。产生原因是有些数据无法获取,或者获取成本过高,或者获取数据时产生误差。
- 异常值。指明显偏离其他观测值的数据。
数据清晰需要处理脏数据,包括删除无关数据、重复数据,处理缺失值、异常值。
缺失值处理: 使用NA表示,is.na识别是否存在缺失值。缺失值常见处理方法:
- 删除法:使用
na.omit()移除缺失行,该方法适用于缺失目标影响不大的情况。 - 替换法:如果缺少数值型变量,使用均值代替;非数值型变量使用其他全部有效观测值的中位数或众数进行替换。
- 插补法:回归插补法(利用回归模型预测缺失值)、多重插补法(使用mice函数包产生缺失值随机样本)。
异常值处理: 使用箱线图、散点图进行识别,如超过上下四分位数 +/- 1.5倍上下四分位数间距的为异常值。还可以使用标准差寻找。异常值的处理方法是:
- 直接删除。如果样本量很少,或者删除后影响整个数据集,不建议删除。
- 视为缺失值,利用缺失值的方法处理。
- 平均值修正。使用前后两个观测值的平均值修正。
- 不处理。直接在异常值的数据集上进行挖掘建模。
数据集成
将多个数据源的数据集成到一个数据仓库中。R中的数据集成是指将储存在两个数据框中的数据以关键词为依据,以行为单位做列合并。可使用merge()函数,格式为`merge(数据框1, 数据框2, by = ‘关键词’),合并后按关键词取值升序排列。
统一实体。常见的实体不一致为同名不同义、同义不同名、单位不统一。
数据集成中往往出现冗余:同一属性多次出现;同一属性命名不一致,导致重复。可以在数据集成前对冗余部分分析,统一实体。
数据变换
数据变换的目的是把数据变换成适合进一步挖掘的格式。常见方法包括简单函数变换、规范化处理、连续变量的离散化、变量属性的构建。
简单函数变换: 包括平方、开方、取对数、差分运算。
规范化处理: 将差别很大的原始数据,变换为[-1,1]或者[0,1]之间的数据。常见的规范化方法包括最小-最大值法,零-均值规范化、小数定标规范化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
# 最小-最大值法
b1 <- (data[,1] - min(data[,1]))/(max(data[,1] - min(data[,1])) # 第一列
b2 <- (data[,2] - min(data[,2]))/(max(data[,2] - min(data[,2])) # 第二列
b3 <- (data[,3] - min(data[,3]))/(max(data[,3] - min(data[,3])) # 第三列
b4 <- (data[,4] - min(data[,4]))/(max(data[,4] - min(data[,4])) # 第四列
data_scatter <- cbind(b1, b2, b3)
# 零-均值规范化
data_zscore <- scale(data) # 公式 (x - 均值)/标准差
# 小数定标规范化
i1 <- ceiling(log(max(abs(data[,1])),10)) # 指数
c1 <- data[,1]/10^i1
i2 <- ceiling(log(max(abs(data[,2])),10)) # 指数
c2 <- data[,1]/10^i2
i3 <- ceiling(log(max(abs(data[,3])),10)) # 指数
c3 <- data[,1]/10^i3
i4 <- ceiling(log(max(abs(data[,4])),10)) # 指数
c4 <- data[,1]/10^i4
data_dot <- cbind(c1,c2,c3,c4)
# 打印结果
options(digits = 4)
data;data_scatter;data_zscore; data_dot
—|—
连续属性离散化: 一些分类算法,要求数据是分类属性形式。
首先,在数据集中设定若干个离散划分点,把数据集划分为离散化区间;其次,用不同的符号或整数值代表落在每个子区间的数据值。
常用的离散方法包括等宽法、等频法、一维聚类。
数据规约
数据规约的目的是提高建模的准确性、使用少量且有代表性的数据大幅缩减数据挖掘所需时间、降低数据储存成本。
属性规约 :目的是寻找出能反映原始数据集概率分布的最小属性子集,常用方法如下:

(上图来源《R语言数据分析与挖掘实战》)
主成分分析方法见R语言教程|带你搞清楚主成分分析(PCA)并完成分析。
数值规约: 选择替代的、较小的数据来减少数据量。包括有参数方法和无参数方法。
有参数方法无需存放数据,只存放参数,如回归(线性回归和多元回归)和对数线性模型。
无参数方法需要储存实际数据,如直方图、聚类、抽样。
主要数据预处理函数
主要函数如下:
| 函数名 | 函数功能 | 格式 |
|---|---|---|
| lm() | 利用因变量与自变量建立线性回归模型 | m <- lm(y~x1 + x2 + …,data) |
| predict() | 依据已有模型对数据进行预测 | predict(model, newdata) |
| mice() | 对缺失数据进行多重插补 | - |
| which() | 返回服从条件的观测所在位置 | which(约束条件) |
| scale() | 对数据进行零-均值规范化 | Z <- scale(X, center = TRUE, scale = TRUE) |
| rnorm() | 随机产生服从正态分布的一列数 | X <- rnorm(n , u, d^2) |
| ceiling() | 向上舍入接近的整数 | Z <- ceilling(X) |
| kmeans() | 对数据进行快速聚类分析 | Z <- kmeans(X, m) |
| dwt() | 对数据进行小波分解 | Z <- dwt(X, n, levels = m) |
| princomp() | 对指标变量矩阵进行主成分分析 | Z <- princomp(X, cor=TURE) |
(上图来源《R语言数据分析与挖掘实战》 P61)