2022年阅读札记
2022年读书数量和读书笔记相比2021年少了不少,但阅读品味和信息获取、加工速度提升了不少,对阅读和信息分析有了新的认知。
2022年思想状态变化很大,大致分成三个阶段:1-3月,4-9月,10-12月。伴随思想状态变化,年初制定的阅读进度也有所影响,如4月份开始,在开智学堂报名的《人性大师阅读课》就没再学习了,第一次在开智捐了学费。好在始终没有放弃阅读,书籍成了整理思绪的港湾,在阅读过程中获得诸多有益思路。
打工VS创业,两套不同的价值创造系统
打工者是用时间换取金钱,创业者是在打造赚钱系统。打工者离开工作岗位后,就没有了收益,需要继续寻找下一份工作,继续用时间换取金钱。创业者则是在构造一个即使不工作,也能带来收益的系统。很多人把自己没有赚到钱,归结为不够努力,实际上不是你不努力,而是你努力的层次已经决定了天花板。
从长远看,打工是高风险,低回报的事。按照别人设计好的路线行走,必然意味着获得社会平均工资,意味着超级内卷。用月薪的量级评估价值的话,打工者的月薪差别是3000,5000,1万,3万,5万,10万这几个量级,大部分人终其一生月薪也难以超越3万。
如何有效地培养管理者|提升管理技能?
管理不是什么?管理不是坐在书斋里学会的,不是教会的。
管理是什么?管理是科学、艺术和手艺的结合。管理根植于实践,以行动和结果为导向,管理的目的是实现组织特定的目标。
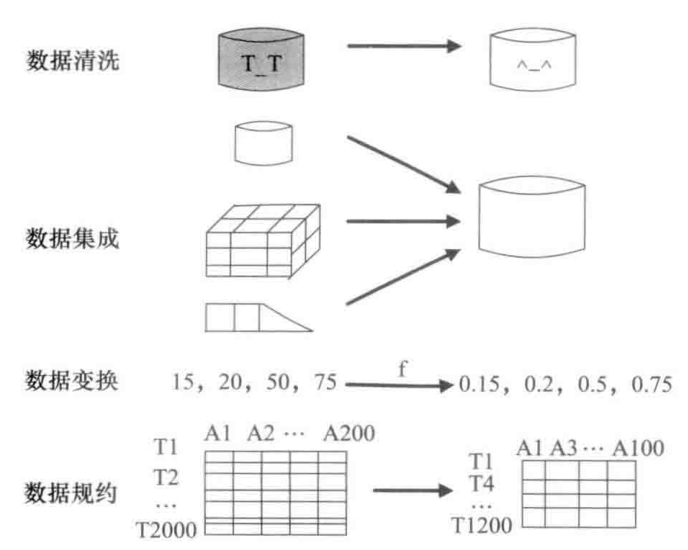
R语言|数据预处理方法
数据预处理的主要内容包括:
你属于哪一类农业从业者/新农人?
最近一直在思考,一些当初很看好的项目,为啥就黄了呢?
深夜,我又翻看和对比了一些跟踪的项目,有的项目日渐衰落,失败只是迟早的事;有的项目苦苦挣扎,不知曙光何时到来;有的项目迅速发展,势如破竹。我望着窗外,喝了一口啤酒,心里很不是滋味,怎么突然就这样了呢?当初的豪言壮语怎么被现实打得支离破碎。